Spark性能调优
1 Spark任务计算时间评估
可以用下面三个公式来近似估计spark任务的执行时间。
$$ 任务执行时间 ≈ \frac{任务计算总时间 + shuffle总时间 + GC垃圾回收总时间} {任务有效并行度}$$
$$ 任务有效并行度 ≈ \frac{min(任务并行度, partition分区数量)} {数据倾斜度\times 计算倾斜度} $$
$$ 任务并行度 ≈ executor数量 \times 每个executor的core数量 $$
可以用下面两个公式来说明spark在executor上的内存分配。
$$ executor申请的内存 ≈ 堆内内存(堆内内存由多个core共享) + 堆外内存 $$
$$ 堆内内存 ≈ storage内存+execution内存+other内存 $$
以下是对上述公式中涉及到的一些概念的初步解读。
任务计算总时间:假设由一台无限内存的同等CPU配置的单核机器执行该任务,所需要的运行时间。通过缓存避免重复计算,通过mapPartitions代替map以减少诸如连接数据库,预处理广播变量等重复过程,都是减少任务计算总时间的例子。
shuffle总时间:任务因为reduceByKey,join,sortBy等shuffle类算子会触发shuffle操作产生的磁盘读写和网络传输的总时间。shuffle操作的目的是将分布在集群中多个节点上的同一个key的数据,拉取到同一个节点上,以便让一个节点对同一个key的所有数据进行统一处理。 shuffle过程首先是前一个stage的一个shuffle write即写磁盘过程,中间是一个网络传输过程,然后是后一个stage的一个shuffle read即读磁盘过程。shuffle过程既包括磁盘读写,又包括网络传输,非常耗时。因此如有可能,应当避免使用shuffle类算子。例如用map+broadcast的方式代替join过程。退而求其次,也可以在shuffle之前对相同key的数据进行归并,减少shuffle读写和传输的数据量。此外,还可以应用一些较为高效的shuffle算子来代替低效的shuffle算子。例如用reduceByKey/aggregateByKey来代替groupByKey。最后,shuffle在进行网络传输的过程中会通过netty使用JVM堆外内存,spark任务中大规模数据的shuffle可能会导致堆外内存不足,导致任务挂掉,这时候需要在配置文件中调大堆外内存。
GC垃圾回收总时间:当JVM中execution内存不足时,会启动GC垃圾回收过程。执行GC过程时候,用户线程会终止等待。因此如果execution内存不够充分,会触发较多的GC过程,消耗较多的时间。在spark2.0之后excution内存和storage内存是统一分配的,不必调整excution内存占比,可以提高executor-memory来降低这种可能。或者减少executor-cores来降低这种可能(这会导致任务并行度的降低)。
任务有效并行度:任务实际上平均被多少个core执行。它首先取决于可用的core数量。当partition分区数量少于可用的core数量时,只会有partition分区数量的core执行任务,因此一般设置分区数是可用core数量的2倍以上20倍以下。此外任务有效并行度严重受到数据倾斜和计算倾斜的影响。有时候我们会看到99%的partition上的数据几分钟就执行完成了,但是有1%的partition上的数据却要执行几个小时。这时候一般是发生了数据倾斜或者计算倾斜。这个时候,我们说,任务实际上有效的并行度会很低,因为在后面的这几个小时的绝大部分时间,只有很少的几个core在执行任务。
任务并行度:任务可用core的数量。它等于申请到的executor数量和每个executor的core数量的乘积。可以在spark-submit时候用num-executor和executor-cores来控制并行度。此外,也可以开启spark.dynamicAllocation.enabled根据任务耗时动态增减executor数量。虽然提高executor-cores也能够提高并行度,但是当计算需要占用较大的存储时,不宜设置较高的executor-cores数量,否则可能会导致executor内存不足发生内存溢出OOM。
partition分区数量:分区数量越大,单个分区的数据量越小,任务在不同的core上的数量分配会越均匀,有助于提升任务有效并行度。但partition数量过大,会导致更多的数据加载时间,一般设置分区数是可用core数量的2倍以上20倍以下。可以在spark-submit中用spark.default.parallelism来控制RDD的默认分区数量,可以用spark.sql.shuffle.partitions来控制SparkSQL中给shuffle过程的分区数量。
数据倾斜度:数据倾斜指的是数据量在不同的partition上分配不均匀。一般来说,shuffle算子容易产生数据倾斜现象,某个key上聚合的数据量可能会百万千万之多,而大部分key聚合的数据量却只有几十几百个。一个partition上过大的数据量不仅需要耗费大量的计算时间,而且容易出现OOM。对于数据倾斜,一种简单的缓解方案是增大partition分区数量,但不能从根本上解决问题。一种较好的解决方案是利用随机数构造数量为原始key数量1000倍的中间key。大概步骤如下,利用1到1000的随机数和当前key组合成中间key,中间key的数据倾斜程度只有原来的1/1000, 先对中间key执行一次shuffle操作,得到一个数据量少得多的中间结果,然后再对我们关心的原始key进行shuffle,得到一个最终结果。
计算倾斜度:计算倾斜指的是不同partition上的数据量相差不大,但是计算耗时相差巨大。考虑这样一个例子,我们的RDD的每一行是一个列表,我们要计算每一行中这个列表中的数两两乘积之和,这个计算的复杂度是和列表长度的平方成正比的,因此如果有一个列表的长度是其它列表平均长度的10倍,那么计算这一行的时间将会是其它列表的100倍,从而产生计算倾斜。计算倾斜和数据倾斜的表现非常相似,我们会看到99%的partition上的数据几分钟就执行完成了,但是有1%的partition上的数据却要执行几个小时。计算倾斜和shuffle无关,在map端就可以发生。计算倾斜出现后,一般可以通过舍去极端数据或者改变计算方法优化性能。
堆内内存:on-heap memory, 即Java虚拟机直接管理的存储,由JVM负责垃圾回收GC。由多个core共享,core越多,每个core实际能使用的内存越少。core设置得过大容易导致OOM,并使得GC时间增加。
堆外内存:off-heap memory, 不受JVM管理的内存, 可以精确控制申请和释放, 没有GC问题。一般shuffle过程在进行网络传输的过程中会通过netty使用到堆外内存。
2 调优顺序
如果程序执行太慢,调优的顺序一般如下:
1,首先调整任务并行度,并调整partition分区。
2,尝试定位可能的重复计算,并优化之。
3,尝试定位数据倾斜问题或者计算倾斜问题并优化之。
4,如果shuffle过程提示堆外内存不足,考虑调高堆外内存。
5,如果发生OOM或者GC耗时过长,考虑提高executor-memory或降低executor-core。
3 Spark调优案例
3.1 开发习惯调优
资源配置优化
#提交python写的任务
spark-submit --master yarn \
--deploy-mode cluster \
--executor-memory 12G \
--driver-memory 12G \
--num-executors 100 \
--executor-cores 8 \
--conf spark.yarn.maxAppAttempts=2 \
--conf spark.task.maxFailures=10 \
--conf spark.stage.maxConsecutiveAttempts=10 \
--conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=./anaconda3.zip/anaconda3/bin/python #指定excutors的Python环境
--conf spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON = ./anaconda3.zip/anaconda3/bin/python #cluster模式时候设置
--archives viewfs:///user/hadoop-xxx/yyy/anaconda3.zip #上传到hdfs的Python环境
--files data.csv,profile.txt
--py-files pkg.py,tqdm.py
pyspark_demo.py
优化后:
#提交python写的任务
spark-submit --master yarn \
--deploy-mode cluster \
--executor-memory 12G \
--driver-memory 12G \
--num-executors 100 \
--executor-cores 2 \
--conf spark.yarn.maxAppAttempts=2 \
--conf spark.default.parallelism=1600 \
--conf spark.sql.shuffle.partitions=1600 \
--conf spark.memory.offHeap.enabled=true \
--conf spark.memory.offHeap.size=2g\
--conf spark.task.maxFailures=10 \
--conf spark.stage.maxConsecutiveAttempts=10 \
--conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=./anaconda3.zip/anaconda3/bin/python #指定excutors的Python环境
--conf spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON = ./anaconda3.zip/anaconda3/bin/python #cluster模式时候设置
--archives viewfs:///user/hadoop-xxx/yyy/anaconda3.zip #上传到hdfs的Python环境
--files data.csv,profile.txt
--py-files pkg.py,tqdm.py
pyspark_demo.py
这里主要减小了 executor-cores数量,一般设置为1~4,过大的数量可能会造成每个core计算和存储资源不足产生OOM,也会增加GC时间。此外也将默认分区数调到了1600,并设置了2G的堆外内存。
尽可能复用同一个RDD,避免重复创建,并且适当持久化数据
这种开发习惯是需要我们对于即将要开发的应用逻辑有比较深刻的思考,并且可以通过code review来发现的,讲白了就是要记得我们创建过啥数据集,可以复用的尽量广播(broadcast)下,能很好提升性能。
# 最低级写法,相同数据集重复创建。
rdd1 = sc.textFile("./test/data/hello_samshare.txt", 4) # 这里的 4 指的是分区数量
rdd2 = sc.textFile("./test/data/hello_samshare.txt", 4) # 这里的 4 指的是分区数量
print(rdd1.take(10))
print(rdd2.map(lambda x:x[0:1]).take(10))
# 稍微进阶一些,复用相同数据集,但因中间结果没有缓存,数据会重复计算
rdd1 = sc.textFile("./test/data/hello_samshare.txt", 4) # 这里的 4 指的是分区数量
print(rdd1.take(10))
print(rdd1.map(lambda x:x[0:1]).take(10))
# 相对比较高效,使用缓存来持久化数据
rdd = sc.parallelize(range(1, 11), 4).cache() # 或者persist()
rdd_map = rdd.map(lambda x: x*2)
rdd_reduce = rdd.reduce(lambda x, y: x+y)
print(rdd_map.take(10))
print(rdd_reduce)
下面我们就来对比一下使用缓存能给我们的Spark程序带来多大的效率提升吧,我们先构造一个程序运行时长测量器。
import time
# 统计程序运行时间
def time_me(info="used"):
def _time_me(fn):
@functools.wraps(fn)
def _wrapper(*args, **kwargs):
start = time.time()
fn(*args, **kwargs)
print("%s %s %s" % (fn.__name__, info, time.time() - start), "second")
return _wrapper
return _time_me
下面我们运行下面的代码,看下使用了cache带来的效率提升:
@time_me()
def test(types=0):
if types == 1:
print("使用持久化缓存")
rdd = sc.parallelize(range(1, 10000000), 4)
rdd1 = rdd.map(lambda x: x*x + 2*x + 1).cache() # 或者 persist(StorageLevel.MEMORY_AND_DISK_SER)
print(rdd1.take(10))
rdd2 = rdd1.reduce(lambda x, y: x+y)
rdd3 = rdd1.reduce(lambda x, y: x + y)
rdd4 = rdd1.reduce(lambda x, y: x + y)
rdd5 = rdd1.reduce(lambda x, y: x + y)
print(rdd5)
else:
print("不使用持久化缓存")
rdd = sc.parallelize(range(1, 10000000), 4)
rdd1 = rdd.map(lambda x: x * x + 2 * x + 1)
print(rdd1.take(10))
rdd2 = rdd1.reduce(lambda x, y: x + y)
rdd3 = rdd1.reduce(lambda x, y: x + y)
rdd4 = rdd1.reduce(lambda x, y: x + y)
rdd5 = rdd1.reduce(lambda x, y: x + y)
print(rdd5)
test() # 不使用持久化缓存
time.sleep(10)
test(1) # 使用持久化缓存
# output:
# 不使用持久化缓存
# [4, 9, 16, 25, 36, 49, 64, 81, 100, 121]
# 333333383333334999999
# test used 26.36529278755188 second
# 使用持久化缓存
# [4, 9, 16, 25, 36, 49, 64, 81, 100, 121]
# 333333383333334999999
# test used 17.49532413482666 second
同时我们打开YARN日志来看看:http://localhost:4040/jobs/
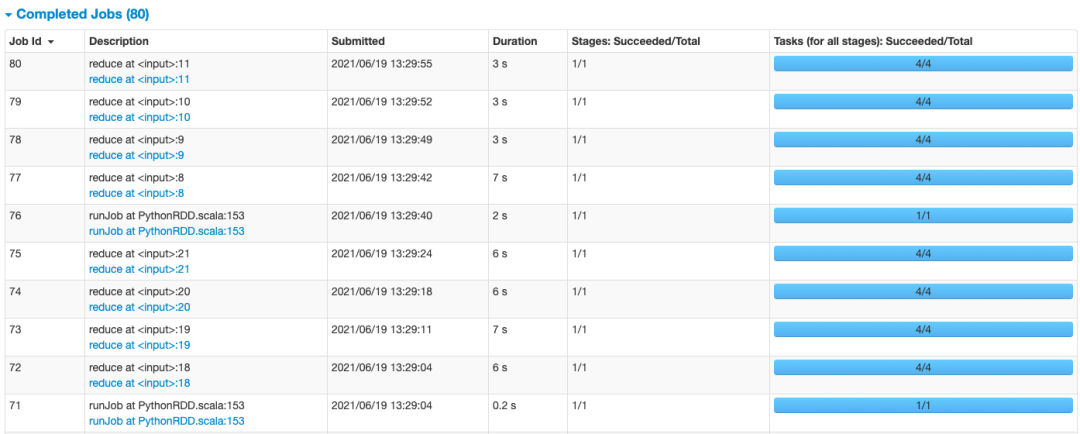
因为我们的代码是需要重复调用RDD1的,当没有对RDD1进行持久化的时候,每次当它被action算子消费了之后,就释放了,等下一个算子计算的时候要用,就从头开始计算一下RDD1。代码中需要重复调用RDD1 五次,所以没有缓存的话,差不多每次都要6秒,总共需要耗时26秒左右,但是,做了缓存,每次就只需要3s不到,总共需要耗时17秒左右。
另外,这里需要提及一下一个知识点,那就是持久化的级别,一般cache的话就是放入内存中,就没有什么好说的,需要讲一下的就是另外一个 persist(),它的持久化级别是可以被我们所配置的:
持久化级别
含义解释
| MEMORY_ONLY | 将数据保存在内存中。如果内存不够存放所有的数据,则数据可能就不会进行持久化。使用cache()方法时,实际就是使用的这种持久化策略,性能也是最高的。 |
| MEMORY_AND_DISK | 优先尝试将数据保存在内存中,如果内存不够存放所有的数据,会将数据写入磁盘文件中。 |
| MEMORY_ONLY_SER | 基本含义同MEMORY_ONLY。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| MEMORY_AND_DISK_SER | 基本含义同MEMORY_AND_DISK。唯一的区别是会先序列化,节约内存。 |
| DISK_ONLY | 使用未序列化的Java对象格式,将数据全部写入磁盘文件中。一般不推荐使用。 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, 等等. | 对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化机制主要用于进行容错。假如某个节点挂掉,节点的内存或磁盘中的持久化数据丢失了,那么后续对RDD计算时还可以使用该数据在其他节点上的副本。如果没有副本的话,就只能将这些数据从源头处重新计算一遍了。一般也不推荐使用。 |
尽量避免使用低性能算子
shuffle类算子算是低性能算子的一种代表,所谓的shuffle类算子,指的是会产生shuffle过程的操作,就是需要把各个节点上的相同key写入到本地磁盘文件中,然后其他的节点通过网络传输拉取自己需要的key,把相同key拉到同一个节点上进行聚合计算,这种操作必然就是有大量的数据网络传输与磁盘读写操作,性能往往不是很好的。
那么,Spark中有哪些算子会产生shuffle过程呢?
操作类别
shuffle类算子
备注
| 分区操作 | repartition()、repartitionAndSortWithinPartitions()、coalesce(shuffle=true) | 重分区操作一般都会shuffle,因为需要对所有的分区数据进行打乱。 |
| 聚合操作 | reduceByKey、groupByKey、sortByKey | 需要对相同key进行操作,所以需要拉到同一个节点上。 |
| 关联操作 | join类操作 | 需要把相同key的数据shuffle到同一个节点然后进行笛卡尔积 |
| 去重操作 | distinct等 | 需要对相同key进行操作,所以需要shuffle到同一个节点上。 |
| 排序操作 | sortByKey等 | 需要对相同key进行操作,所以需要shuffle到同一个节点上。 |
这里进一步介绍一个替代join的方案,因为join其实在业务中还是蛮常见的。
# 原则2:尽量避免使用低性能算子
rdd1 = sc.parallelize([('A1', 211), ('A1', 212), ('A2', 22), ('A4', 24), ('A5', 25)])
rdd2 = sc.parallelize([('A1', 11), ('A2', 12), ('A3', 13), ('A4', 14)])
# 低效的写法,也是传统的写法,直接join
rdd_join = rdd1.join(rdd2)
print(rdd_join.collect())
# [('A4', (24, 14)), ('A2', (22, 12)), ('A1', (211, 11)), ('A1', (212, 11))]
rdd_left_join = rdd1.leftOuterJoin(rdd2)
print(rdd_left_join.collect())
# [('A4', (24, 14)), ('A2', (22, 12)), ('A5', (25, None)), ('A1', (211, 11)), ('A1', (212, 11))]
rdd_full_join = rdd1.fullOuterJoin(rdd2)
print(rdd_full_join.collect())
# [('A4', (24, 14)), ('A3', (None, 13)), ('A2', (22, 12)), ('A5', (25, None)), ('A1', (211, 11)), ('A1', (212, 11))]
# 高效的写法,使用 广播+map 来实现相同效果
# tips1: 这里需要注意的是,用来broadcast的RDD不可以太大,最好不要超过1G
# tips2: 这里需要注意的是,用来broadcast的RDD不可以有重复的key的
rdd1 = sc.parallelize([('A1', 11), ('A2', 12), ('A3', 13), ('A4', 14)])
rdd2 = sc.parallelize([('A1', 211), ('A1', 212), ('A2', 22), ('A4', 24), ('A5', 25)])
# step1: 先将小表进行广播,也就是collect到driver端,然后广播到每个Executor中去。
rdd_small_bc = sc.broadcast(rdd1.collect())
# step2:从Executor中获取存入字典便于后续map操作
rdd_small_dict = dict(rdd_small_bc.value)
# step3:定义join方法
def broadcast_join(line, rdd_small_dict, join_type):
k = line[0]
v = line[1]
small_table_v = rdd_small_dict[k] if k in rdd_small_dict else None
if join_type == 'join':
return (k, (v, small_table_v)) if k in rdd_small_dict else None
elif join_type == 'left_join':
return (k, (v, small_table_v if small_table_v is not None else None))
else:
print("not support join type!")
# step4:使用 map 实现 两个表join的功能
rdd_join = rdd2.map(lambda line: broadcast_join(line, rdd_small_dict, "join")).filter(lambda line: line is not None)
rdd_left_join = rdd2.map(lambda line: broadcast_join(line, rdd_small_dict, "left_join")).filter(lambda line: line is not None)
print(rdd_join.collect())
print(rdd_left_join.collect())
# [('A1', (211, 11)), ('A1', (212, 11)), ('A2', (22, 12)), ('A4', (24, 14))]
# [('A1', (211, 11)), ('A1', (212, 11)), ('A2', (22, 12)), ('A4', (24, 14)), ('A5', (25, None))]
上面的RDD join被改写为 broadcast+map的PySpark版本实现,不过里面有两个点需要注意:
- tips1: 用来broadcast的RDD不可以太大,最好不要超过1G
- tips2: 用来broadcast的RDD不可以有重复的key的
尽量使用高性能算子
上一节讲到了低效算法,自然地就会有一些高效的算子。
原算子
高效算子(替换算子)
说明
| map | mapPartitions | 直接map的话,每次只会处理一条数据,而mapPartitions则是每次处理一个分区的数据,在某些场景下相对比较高效。(分区数据量不大的情况下使用,如果有数据倾斜的话容易发生OOM) |
| groupByKey | reduceByKey/aggregateByKey | 这类算子会在原节点先map-side预聚合,相对高效些。 |
| foreach | foreachPartitions | 同第一条记录一样。 |
| filter | filter+coalesce | 当我们对数据进行filter之后,有很多partition的数据会剧减,然后直接进行下一步操作的话,可能就partition数量很多但处理的数据又很少,task数量没有减少,反而整体速度很慢;但如果执行了coalesce算子,就会减少一些partition数量,把数据都相对压缩到一起,用更少的task处理完全部数据,一定场景下还是可以达到整体性能的提升。 |
| repartition+sort | repartitionAndSortWithinPartitions | 直接用就是了。 |
广播大变量
如果我们有一个数据集很大,并且在后续的算子执行中会被反复调用,那么就建议直接把它广播(broadcast)一下。当变量被广播后,会保证每个executor的内存中只会保留一份副本,同个executor内的task都可以共享这个副本数据。如果没有广播,常规过程就是把大变量进行网络传输到每一个相关task中去,这样子做,一来频繁的网络数据传输,效率极其低下;二来executor下的task不断存储同一份大数据,很有可能就造成了内存溢出或者频繁GC,效率也是极其低下的。
# 原则4:广播大变量
rdd1 = sc.parallelize([('A1', 11), ('A2', 12), ('A3', 13), ('A4', 14)])
rdd1_broadcast = sc.broadcast(rdd1.collect())
print(rdd1.collect())
print(rdd1_broadcast.value)
# [('A1', 11), ('A2', 12), ('A3', 13), ('A4', 14)]
# [('A1', 11), ('A2', 12), ('A3', 13), ('A4', 14)]
3.2 资源参数调优
如果要进行资源调优,我们就必须先知道Spark运行的机制与流程。
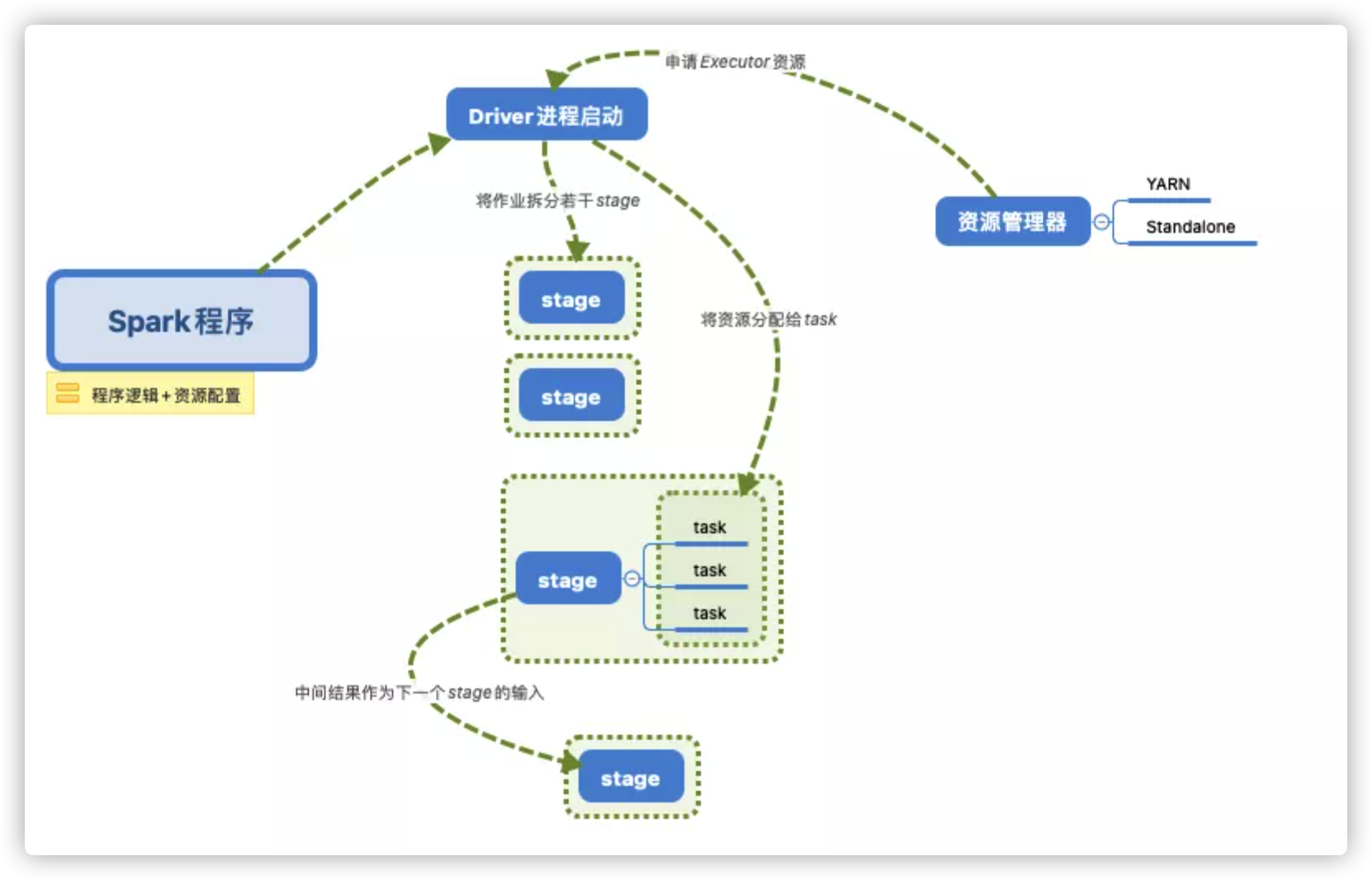
下面我们就来讲解一些常用的Spark资源配置的参数吧,了解其参数原理便于我们依据实际的数据情况进行配置。
1)num-executors
指的是执行器的数量,数量的多少代表了并行的stage数量(假如executor是单核的话),但也并不是越多越快,受你集群资源的限制,所以一般设置50-100左右吧。
2)executor-memory
这里指的是每一个执行器的内存大小,内存越大当然对于程序运行是很好的了,但是也不是无节制地大下去,同样受我们集群资源的限制。假设我们集群资源为500core,一般1core配置4G内存,所以集群最大的内存资源只有2000G左右。num-executors x executor-memory 是不能超过2000G的,但是也不要太接近这个值,不然的话集群其他同事就没法正常跑数据了,一般我们设置4G-8G。
3)executor-cores
这里设置的是executor的CPU core数量,决定了executor进程并行处理task的能力。
4)driver-memory
设置driver的内存,一般设置2G就好了。但如果想要做一些Python的DataFrame操作可以适当地把这个值设大一些。
5)driver-cores
与executor-cores类似的功能。
6)spark.default.parallelism
设置每个stage的task数量。一般Spark任务我们设置task数量在500-1000左右比较合适,如果不去设置的话,Spark会根据底层HDFS的block数量来自行设置task数量。有的时候会设置得偏少,这样子程序就会跑得很慢,即便你设置了很多的executor,但也没有用。
下面说一个基本的参数设置的shell脚本,一般我们都是通过一个shell脚本来设置资源参数配置,接着就去调用我们的主函数。
#!/bin/bash
basePath=$(cd "$(dirname )"$(cd "$(dirname "$0"): pwd)")": pwd)
spark-submit \
--master yarn \
--queue samshare \
--deploy-mode client \
--num-executors 100 \
--executor-memory 4G \
--executor-cores 4 \
--driver-memory 2G \
--driver-cores 2 \
--conf spark.default.parallelism=1000 \
--conf spark.yarn.executor.memoryOverhead=8G \
--conf spark.sql.shuffle.partitions=1000 \
--conf spark.network.timeout=1200 \
--conf spark.python.worker.memory=64m \
--conf spark.sql.catalogImplementation=hive \
--conf spark.sql.crossJoin.enabled=True \
--conf spark.dynamicAllocation.enabled=True \
--conf spark.shuffle.service.enabled=True \
--conf spark.scheduler.listenerbus.eventqueue.size=100000 \
--conf spark.pyspark.driver.python=python3 \
--conf spark.pyspark.python=python3 \
--conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=python3 \
--conf spark.sql.pivotMaxValues=500000 \
--conf spark.hadoop.hive.exec.dynamic.partition=True \
--conf spark.hadoop.hive.exec.dynamic.partition.mode=nonstrict \
--conf spark.hadoop.hive.exec.max.dynamic.partitions.pernode=100000 \
--conf spark.hadoop.hive.exec.max.dynamic.partitions=100000 \
--conf spark.hadoop.hive.exec.max.created.files=100000 \
${bashPath}/project_name/main.py $v_var1 $v_var2
3.3 数据倾斜调优
相信我们对于数据倾斜并不陌生了,很多时间数据跑不出来有很大的概率就是出现了数据倾斜,在Spark开发中无法避免的也会遇到这类问题,而这不是一个崭新的问题,成熟的解决方案也是有蛮多的,今天来简单介绍一些比较常用并且有效的方案。
首先我们要知道,在Spark中比较容易出现倾斜的操作,主要集中在distinct、groupByKey、reduceByKey、aggregateByKey、join、repartition等,可以优先看这些操作的前后代码。而为什么使用了这些操作就容易导致数据倾斜呢?大多数情况就是进行操作的key分布不均,然后使得大量的数据集中在同一个处理节点上,从而发生了数据倾斜。
查看Key 分布
# 针对Spark SQL
hc.sql("select key, count(0) nums from table_name group by key")
# 针对RDD
RDD.countByKey()
Plan A: 过滤掉导致倾斜的key
这个方案并不是所有场景都可以使用的,需要结合业务逻辑来分析这个key到底还需要不需要,大多数情况可能就是一些异常值或者空串,这种就直接进行过滤就好了。
Plan B: 提前处理聚合
如果有些Spark应用场景需要频繁聚合数据,而数据key又少的,那么我们可以把这些存量数据先用hive算好(每天算一次),然后落到中间表,后续Spark应用直接用聚合好的表+新的数据进行二度聚合,效率会有很高的提升。
Plan C: 调高shuffle并行度
# 针对Spark SQL
--conf spark.sql.shuffle.partitions=1000 # 在配置信息中设置参数
# 针对RDD
rdd.reduceByKey(1000) # 默认是200
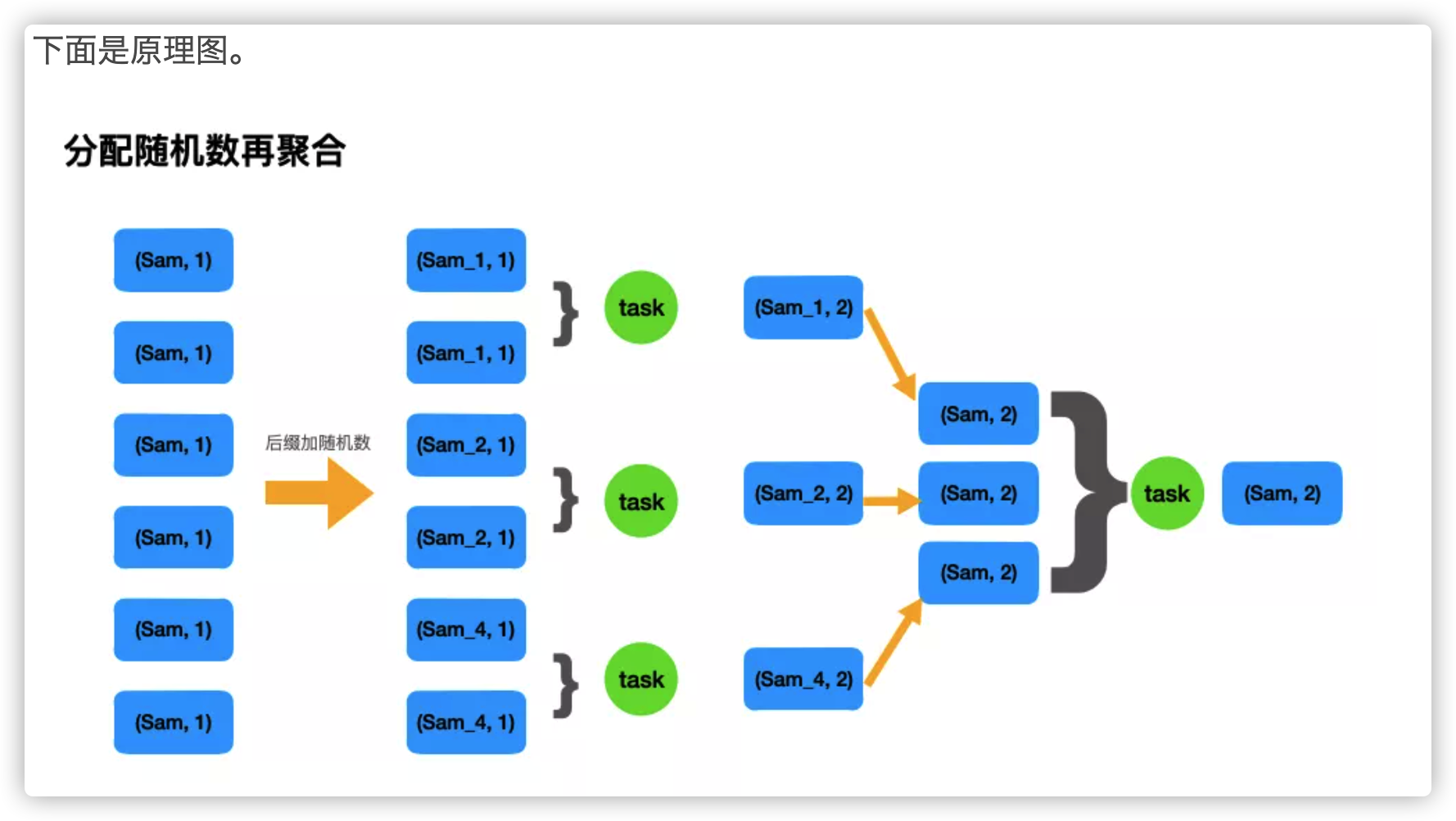
Plan D: 分配随机数再聚合
大概的思路就是对一些大量出现的key,人工打散,从而可以利用多个task来增加任务并行度,以达到效率提升的目的,下面是代码demo,分别从RDD 和 SparkSQL来实现。
# Way1: PySpark RDD实现
import pyspark
from pyspark import SparkContext, SparkConf, HiveContext
from random import randint
import pandas as pd
# SparkSQL的许多功能封装在SparkSession的方法接口中, SparkContext则不行的。
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("sam_SamShare") \
.config("master", "local[4]") \
.enableHiveSupport() \
.getOrCreate()
conf = SparkConf().setAppName("test_SamShare").setMaster("local[4]")
sc = SparkContext(conf=conf)
hc = HiveContext(sc)
# 分配随机数再聚合
rdd1 = sc.parallelize([('sam', 1), ('sam', 1), ('sam', 1), ('sam', 1), ('sam', 1), ('sam', 1)])
# 给key分配随机数后缀
rdd2 = rdd1.map(lambda x: (x[0] + "_" + str(randint(1,5)), x[1]))
print(rdd.take(10))
# [('sam_5', 1), ('sam_5', 1), ('sam_3', 1), ('sam_5', 1), ('sam_5', 1), ('sam_3', 1)]
# 局部聚合
rdd3 = rdd2.reduceByKey(lambda x,y : (x+y))
print(rdd3.take(10))
# [('sam_5', 4), ('sam_3', 2)]
# 去除后缀
rdd4 = rdd3.map(lambda x: (x[0][:-2], x[1]))
print(rdd4.take(10))
# [('sam', 4), ('sam', 2)]
# 全局聚合
rdd5 = rdd4.reduceByKey(lambda x,y : (x+y))
print(rdd5.take(10))
# [('sam', 6)]
# Way2: PySpark SparkSQL实现
df = pd.DataFrame(5*[['Sam', 1],['Flora', 1]],
columns=['name', 'nums'])
Spark_df = spark.createDataFrame(df)
print(Spark_df.show(10))
Spark_df.createOrReplaceTempView("tmp_table") # 注册为视图供SparkSQl使用
sql = """
with t1 as (
select concat(name,"_",int(10*rand())) as new_name, name, nums
from tmp_table
),
t2 as (
select new_name, sum(nums) as n
from t1
group by new_name
),
t3 as (
select substr(new_name,0,length(new_name) -2) as name, sum(n) as nums_sum
from t2
group by substr(new_name,0,length(new_name) -2)
)
select *
from t3
"""
tt = hc.sql(sql).toPandas()
tt

broadcast+map代替join
该优化策略一般限于有一个参与join的rdd的数据量不大的情况。
%%time
# 优化前:
rdd_age = sc.parallelize([("LiLei",18),("HanMeimei",19),("Jim",17),("LiLy",20)])
rdd_gender = sc.parallelize([("LiLei","male"),("HanMeimei","female"),("Jim","male"),("LiLy","female")])
rdd_students = rdd_age.join(rdd_gender).map(lambda x:(x[0],x[1][0],x[1][1]))
print(rdd_students.collect())
[(‘LiLy’, 20, ‘female’), (‘LiLei’, 18, ‘male’), (‘HanMeimei’, 19, ‘female’), (‘Jim’, 17, ‘male’)] CPU times: user 43.9 ms, sys: 11.6 ms, total: 55.6 ms Wall time: 307 ms
%%time
# 优化后:
rdd_age = sc.parallelize([("LiLei",18),("HanMeimei",19),("Jim",17),("LiLy",20)])
rdd_gender = sc.parallelize([("LiLei","male"),("HanMeimei","female"),("Jim","male"),("LiLy","female")],2)
ages = rdd_age.collect()
broads = sc.broadcast(ages)
def get_age(it):
result = []
ages = dict(broads.value)
for x in it:
name = x[0]
age = ages.get(name,0)
result.append((x[0],age,x[1]))
return iter(result)
rdd_students = rdd_gender.mapPartitions(get_age)
print(rdd_students.collect())
[(‘LiLei’, 18, ‘male’), (‘HanMeimei’, 19, ‘female’), (‘Jim’, 17, ‘male’), (‘LiLy’, 20, ‘female’)] CPU times: user 14.3 ms, sys: 7.43 ms, total: 21.7 ms Wall time: 86.3 ms